
- pub
Flux.1 LoRA と DoRA のトレーニングのための最適化された OneTrainer 設定とコツ(20% 速く)
トレーニングの準備
モデルの選択
まずは、Flux AI モデルを選んでるか確認してね。OneTrainerでは、Fluxのいろんなモデル(dev、pro、schnellなど)をサポートしてるよ。自分のプロジェクトに合ったモデルを使うのが大事。
- モデルを入手する: Hugging Faceみたいな公式のソースからダウンロードしてね。
- モデルを読み込む: OneTrainerのモデル設定に行って、モデルファイルを読み込もう。
環境の設定
ハードウェア要件:
- GPU: 最低でも3060を推奨。4090ならもっと性能アップするね。
- VRAM: 高解像度を扱うために、最低12GBは必要だよ。
- RAM: 最低10GBはあったほうがいいけど、もっとあればなお良し。
ソフトウェア要件:
- オペレーティングシステム: WindowsとLinuxの両方でテスト済み。
- 依存関係: 必要なライブラリとツールがちゃんとインストールされてるかチェックしてね。OneTrainerのドキュメントを見て確認しよう。
詳細な設定と構成
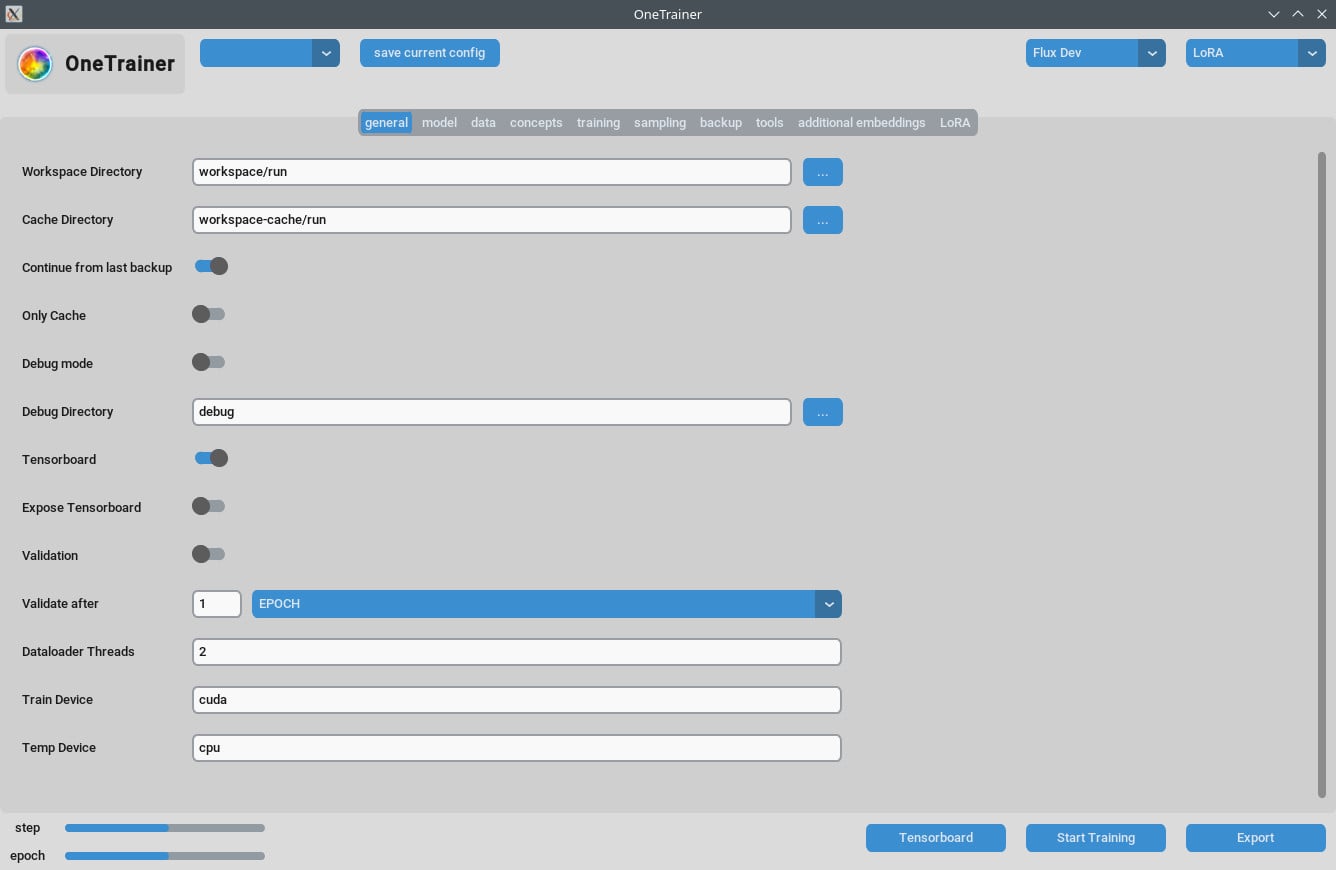
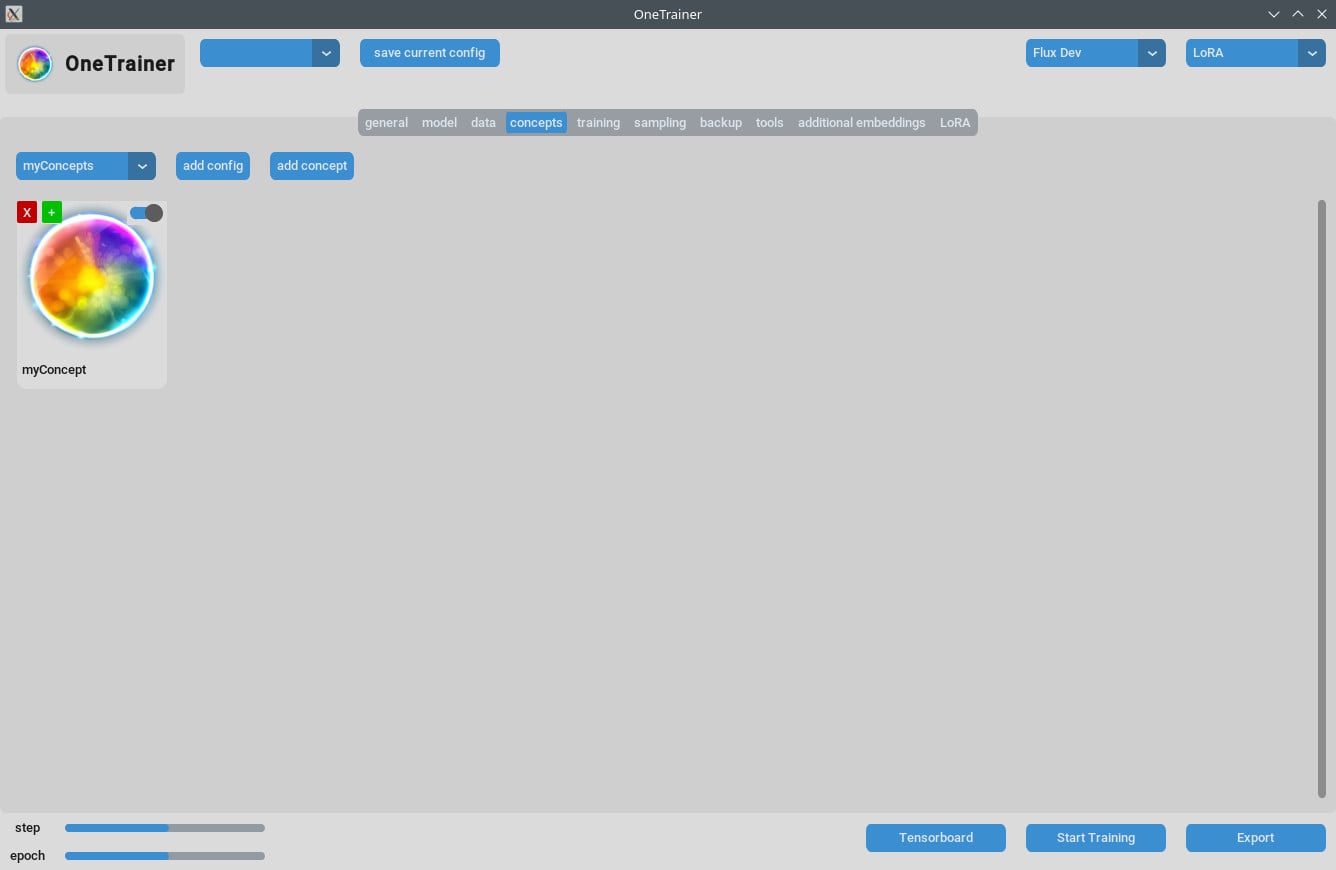
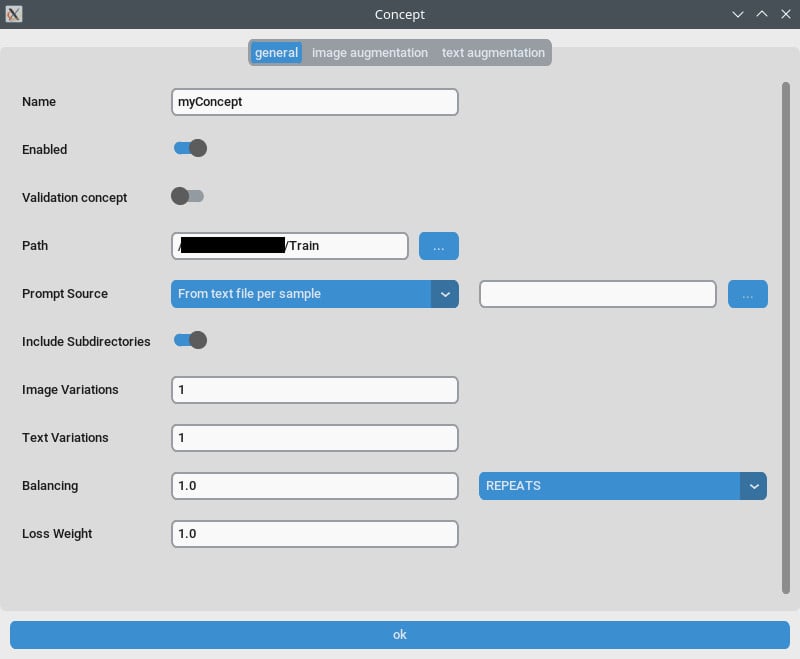
コンセプトタブ / 一般設定
- リピート数:
Repeatsを1に設定してね。リピートの数はトレーニングタブのNumber of Epochsで管理するよ。 - プロンプトソース: 画像ごとの個別なキャプションの代わりに「トリガーワード」を使いたいなら、「single text file」から選ぼう。この設定をトリガーワードやフレーズが入ったテキストファイルに設定してね。
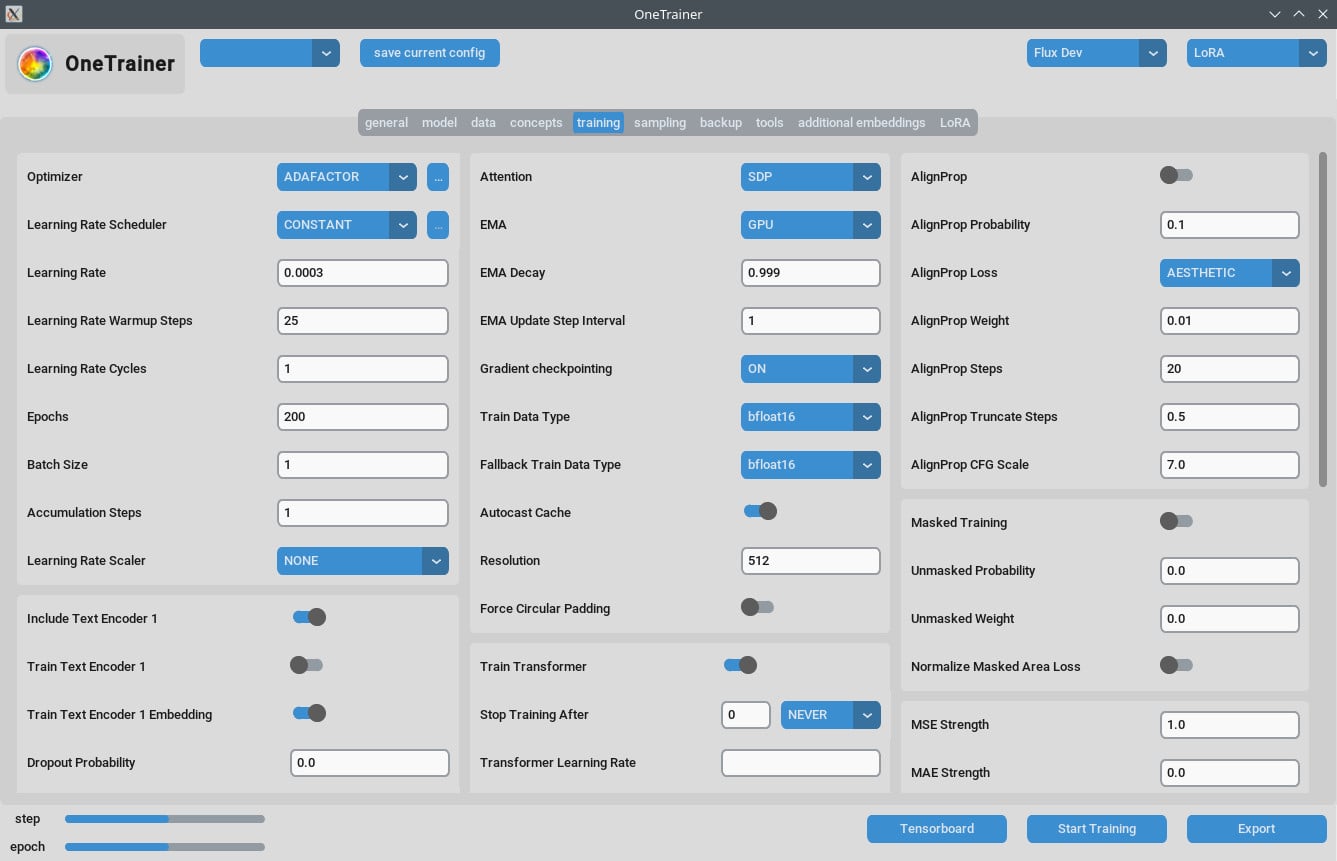
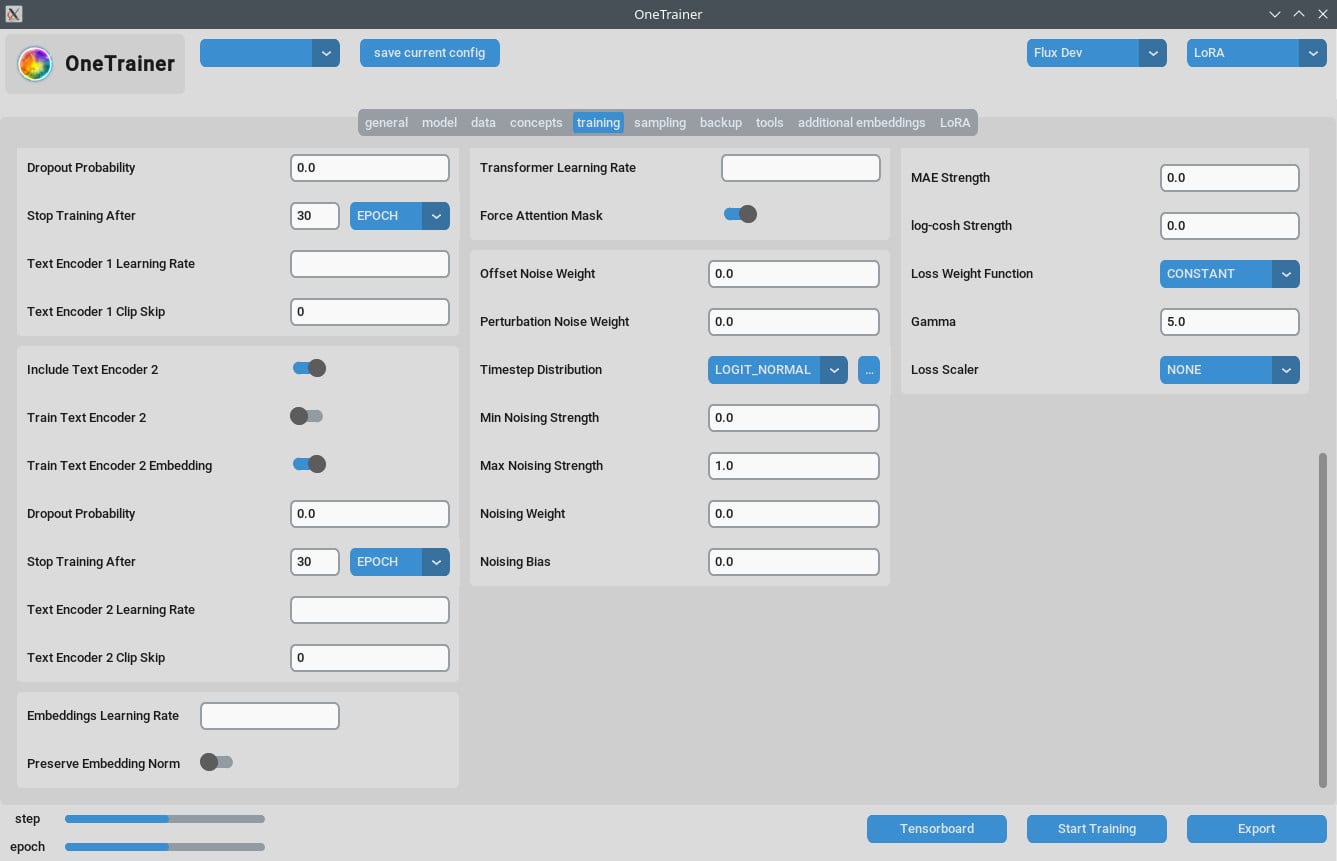
トレーニングタブ
解像度の設定
- 品質向上のために:
- より高品質の出力を得るために、
Resolutionを768か1024に設定しよう。
- より高品質の出力を得るために、
- EMA設定:
- EMA: SDXLトレーニング中に使おう。
- EMA GPU: VRAMを節約するために、EMAを「GPU」から「OFF」に設定してね。
- 学習率:
- 最初は0.0003か0.0004から始めてみよう。必要に応じて調整してね。
- エポックの数:
- 通常、40エポックで良い結果が出るよ。データセットの複雑さに応じて調整してみて。
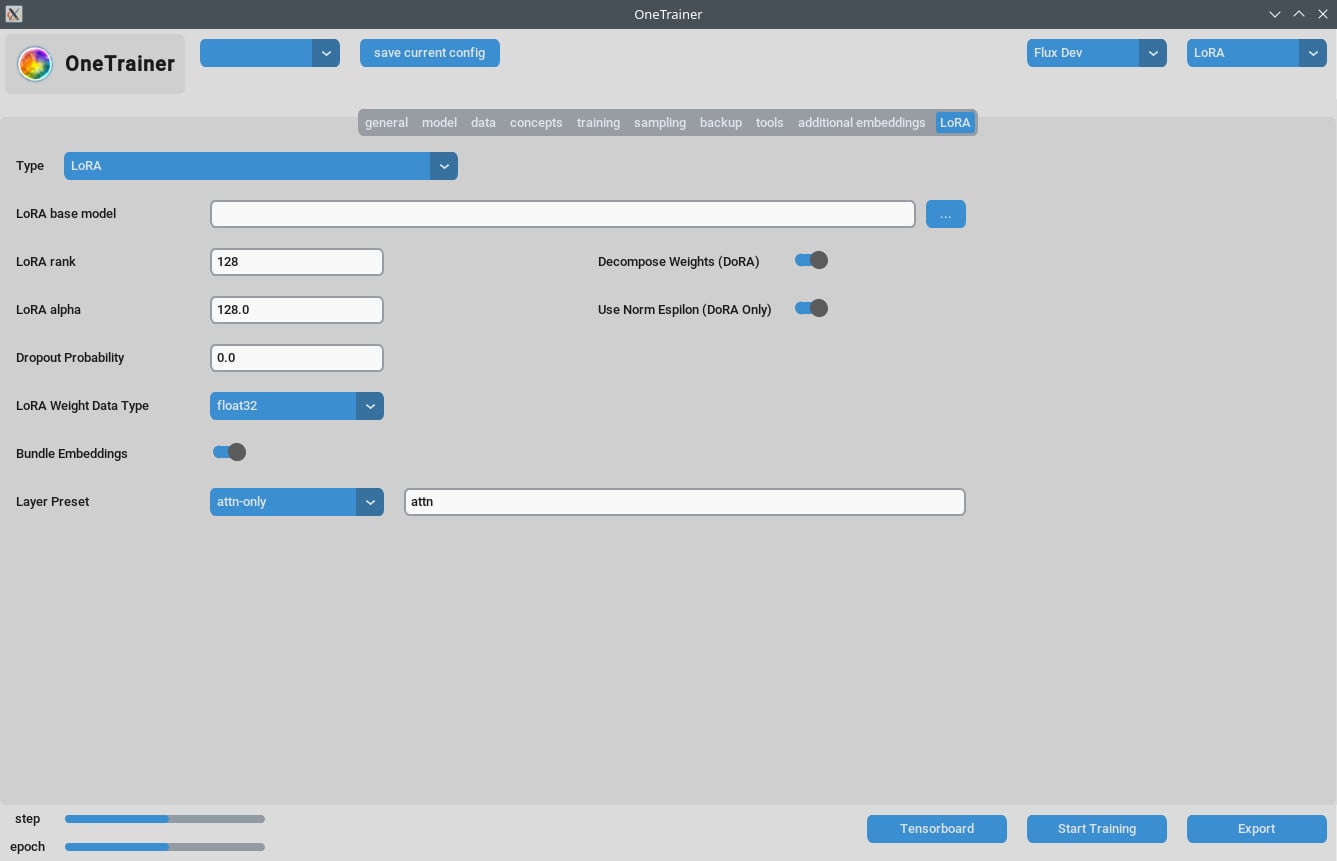
LoRAタブ
- ランクとアルファ:
- これらの値は同じに保つ(例: 64/64, 32/32)か、学習率をそれに合わせて調整してね。
- 結果のLoRAモデル:
- 最近のComfyUIバージョンを使っているなら、更新が適用されているか確認しよう。
パフォーマンス最適化
- グラデーションチェックポイント:
- スピードが遅いなら、これをオフにしてみて。特にハードウェアが高いVRAMをサポートしてる場合ね。
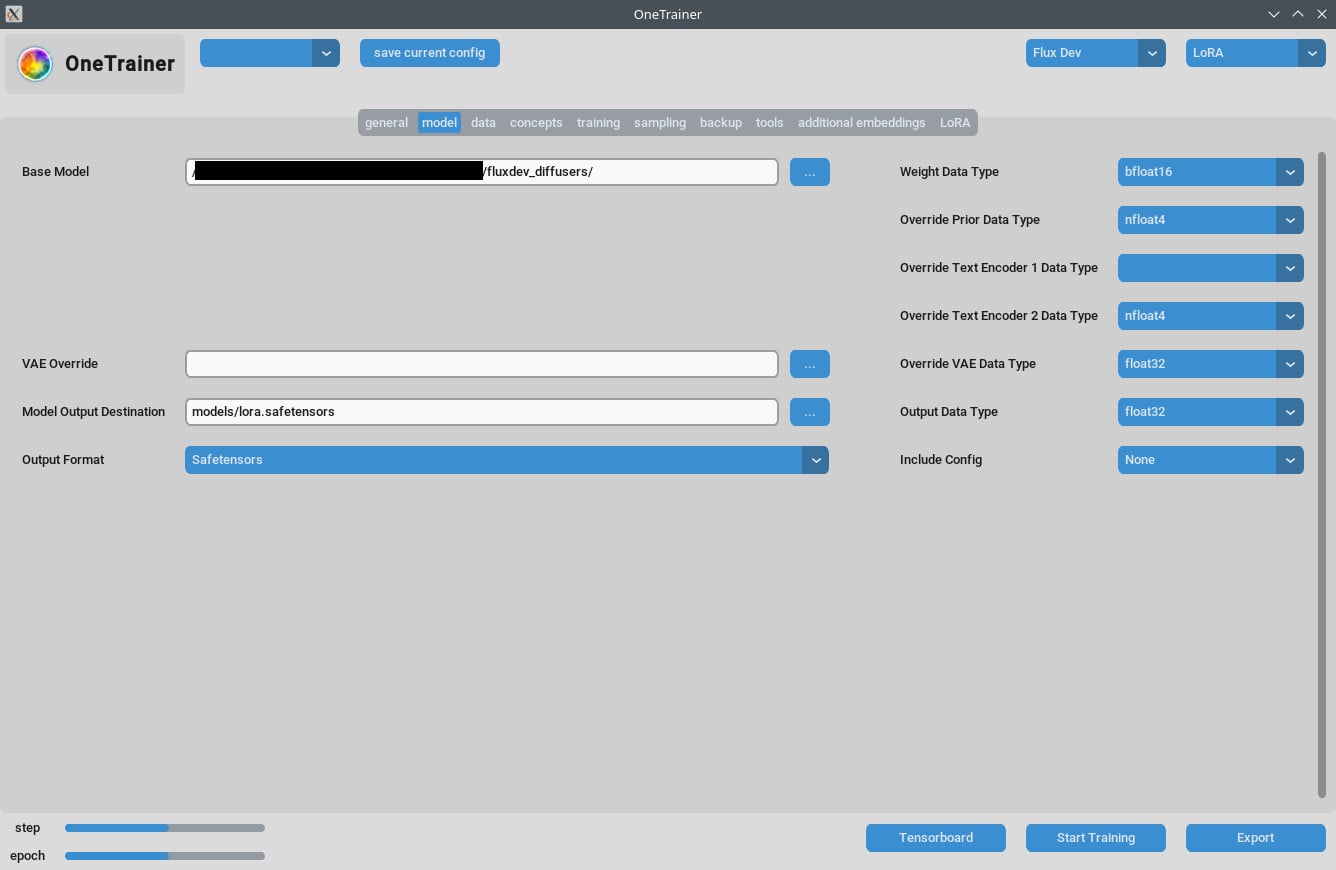
- bf16 vs nfloat4:
- 「モデル」タブで、
Override Prior Data Typeをbf16に切り替えると、品質が上がるかも。この設定はVRAMとスピードに影響があるよ。
- 「モデル」タブで、
サンプリングの問題処理
- 一部のユーザーはサンプリング中にOut Of Memory (OOM) エラーを経験してる。GPUのVRAMが十分か確認してね。
- 定期的にOneTrainerをアップデートして、バグ修正やパッチを取り入れよう。
マルチコンセプトトレーニングのヒント
現在の制限
- 同じセッションで異なるトリガーワードで複数の人をトレーニングするのは、たいていうまくいかないよ。
- 異なるオブジェクトやシチュエーション(例えば、トレーニングシューズと特定の車)でのトレーニングのほうが効果的。
ベストプラクティス
- 短いキャプション:
- 短い、自然な言葉のキャプションを使うと、数百ステップでうまくいくことが多いよ。
- LoRAのスタッキング:
- コンセプトとキャラクターのLoRAをスタックするのが、組み合わせてトレーニングするよりも良い結果を出すよ。
キャプションとデータ管理
- トレーニングデータをしっかり整理するのがポイント。エポックの数はデータの複雑さによるからね。
- 短くて明確なキャプションを使うと、トレーニングの効率が格段にアップするよ。
よくある質問
Q1: OneTrainerはFlux.1以外のモデルにも使える?
もちろん!OneTrainerはSD 1.5、SDXLなどもサポートしてるよ。モデルによって設定はちょっと変わるけどね。
Q2: OneTrainerは自動的にコンセプト名をトリガーワードとして使うの?
うん、コンセプト名がトリガーワードになれるよ。プロジェクトに意味のある名前にしてね。
Q3: トレーニング中にVRAMをうまく管理するにはどうすればいい?
Gradient CheckpointingをCPU_OFFLOADに設定すると、VRAMの使用を減らせるよ。スピードにも大きな影響はないから試してみて。
Q4: NF4を使うとフルプレシジョンレイヤーに比べてどうなる?
NF4はVRAM使用量が減るけど、少し品質が落ちるかも。フルプレシジョンレイヤーは品質を保てるけど、VRAMは多めに必要だよ。
Q5: LoRAモデルのサイズを減らすには?
RankとAlphaの値を下げるか、LoRA weight data typeをbfloat16に設定できるよ。サイズは減るけど、品質に影響が出るかもしれないから注意してね。
Q6: OneTrainerはマルチ解像度トレーニングに対応してる?
うん、OneTrainerはマルチ解像度トレーニングに対応してるよ。設定方法はOneTrainerのウィキを見て確認してね。
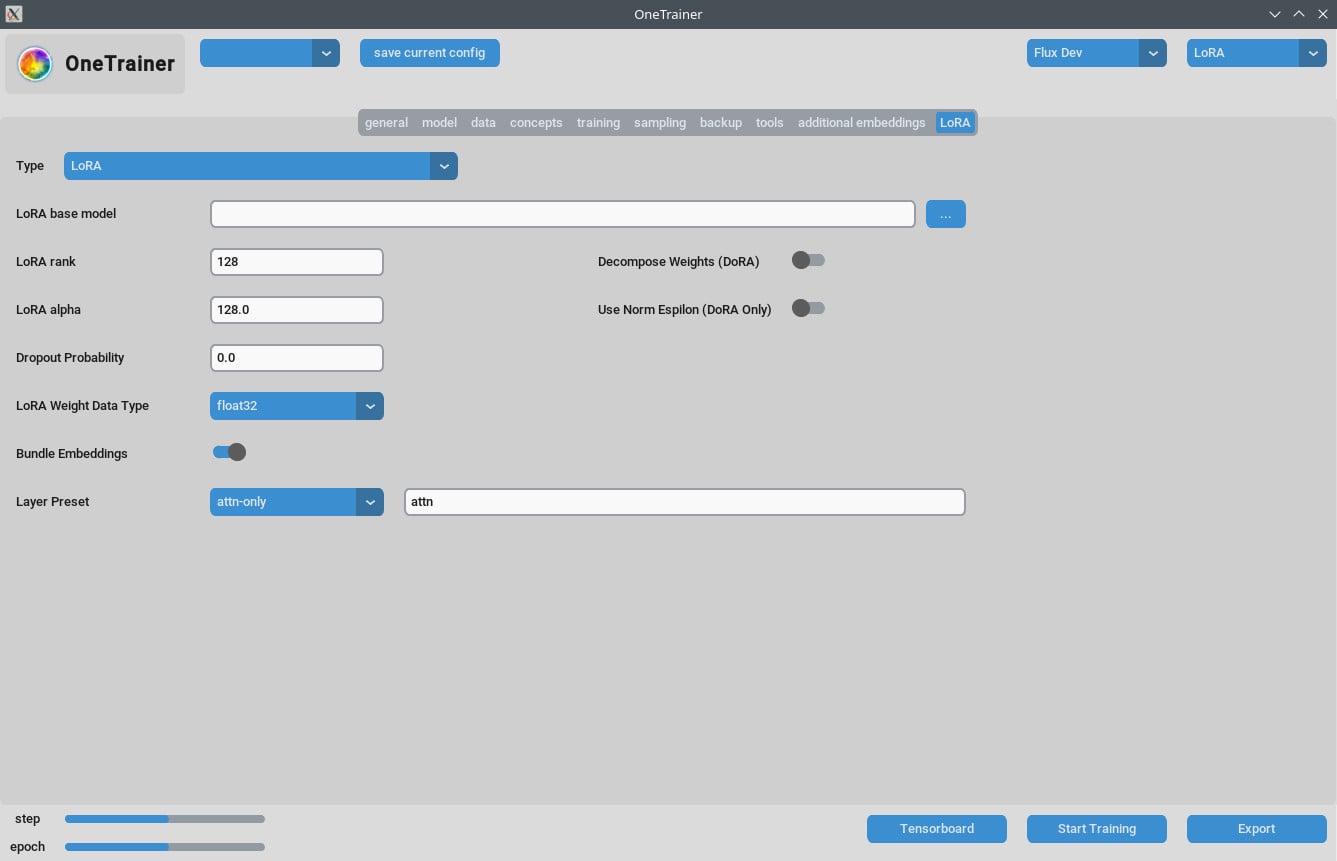
Q7: DoRAを使ってて画像がピンクの静止画になるのはどうすればいい?
アテンションレイヤーの設定を確認してね。「フル」に設定しないようにすると、問題が解決することが多いよ。
Q8: OneTrainerで複数の被写体をどう扱う?
異なる被写体ごとにリピート値を設定してバランスよくトレーニングするのがポイント。データをしっかり整理して、両方の被写体に対して均等にトレーニングを受けさせよう。
Q9: OneTrainerに「スプリットモード」はあるの?
OneTrainerには「スプリットモード」はないけど、Gradient Checkpointingの設定をCPU_OFFLOADにすると、VRAMをよりうまく管理できるよ。
Q10: 一層多くのVRAMを使いながら、品質を向上させられる設定は?
はい、解像度を上げたり、データタイプやグラデーションチェックポイントの設定を調整することで品質を向上させられるよ。
このガイドでは、Flux AIモデルを使ったOneTrainerの効果的な使い方のすべてのステップ、設定、トラブルシューティングのヒントをまとめたよ。トレーニング楽しんでね!