
- pub
Optimierte OneTrainer Einstellungen und Tipps für Flux.1 LoRA und DoRA Training (20% schneller)
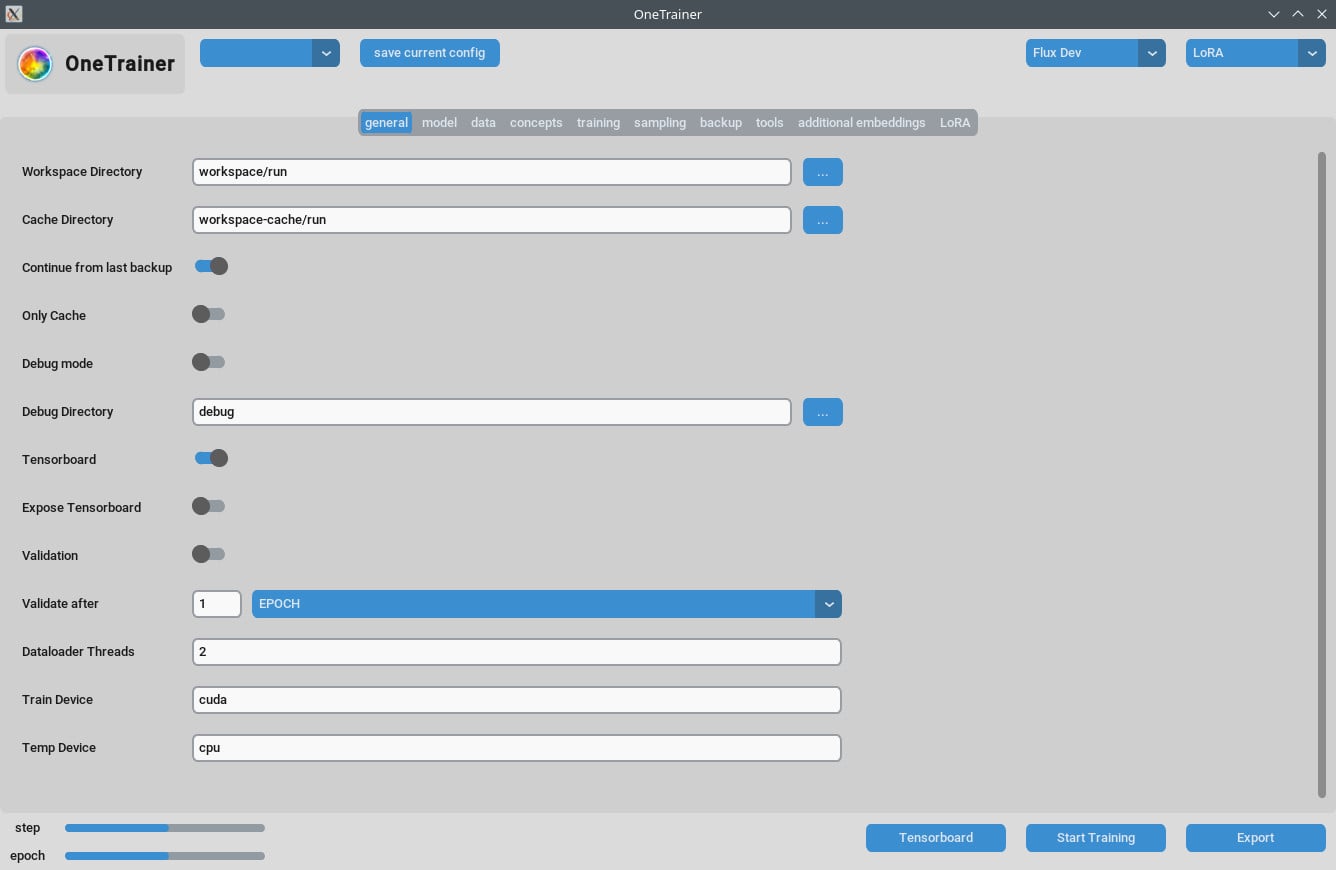
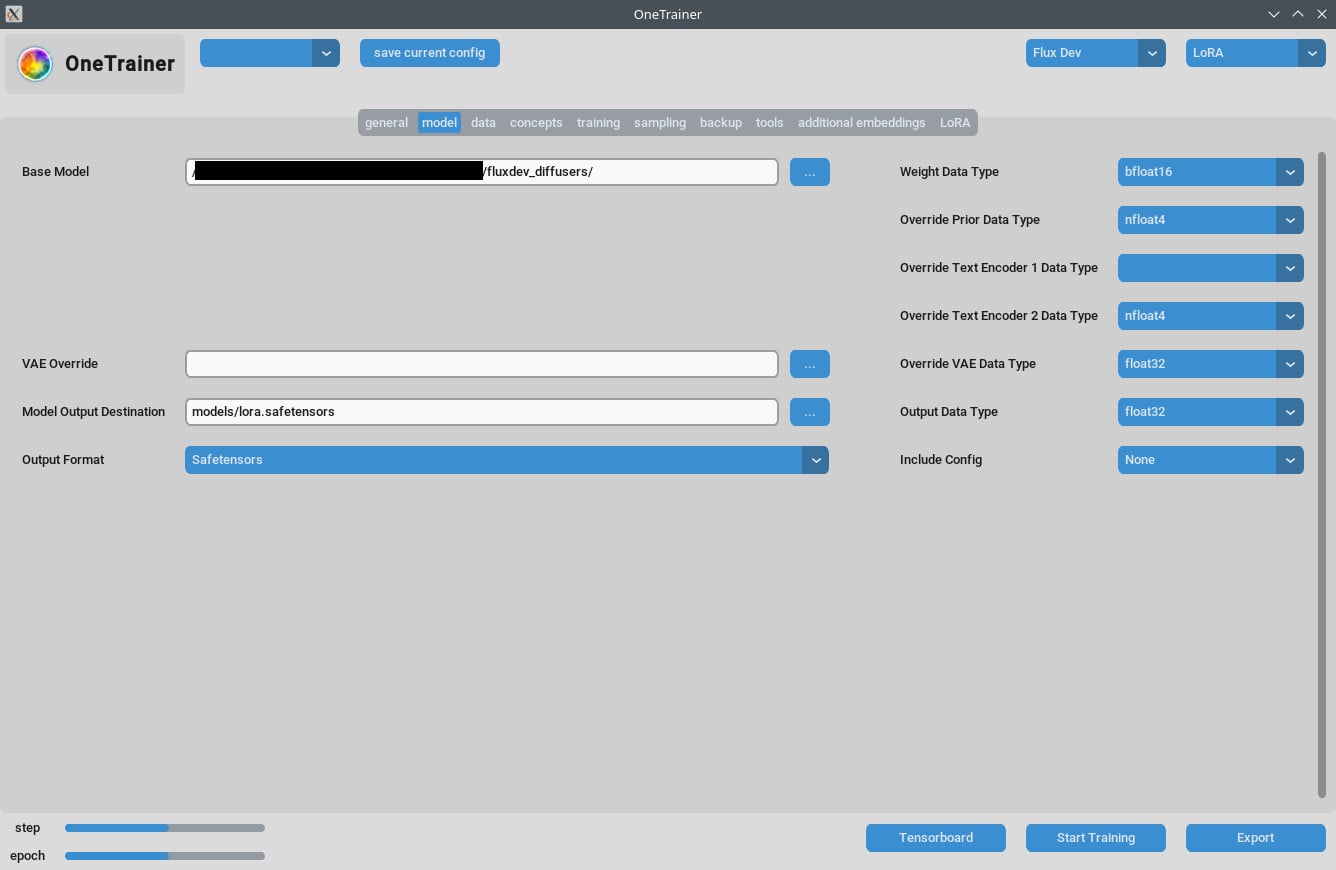
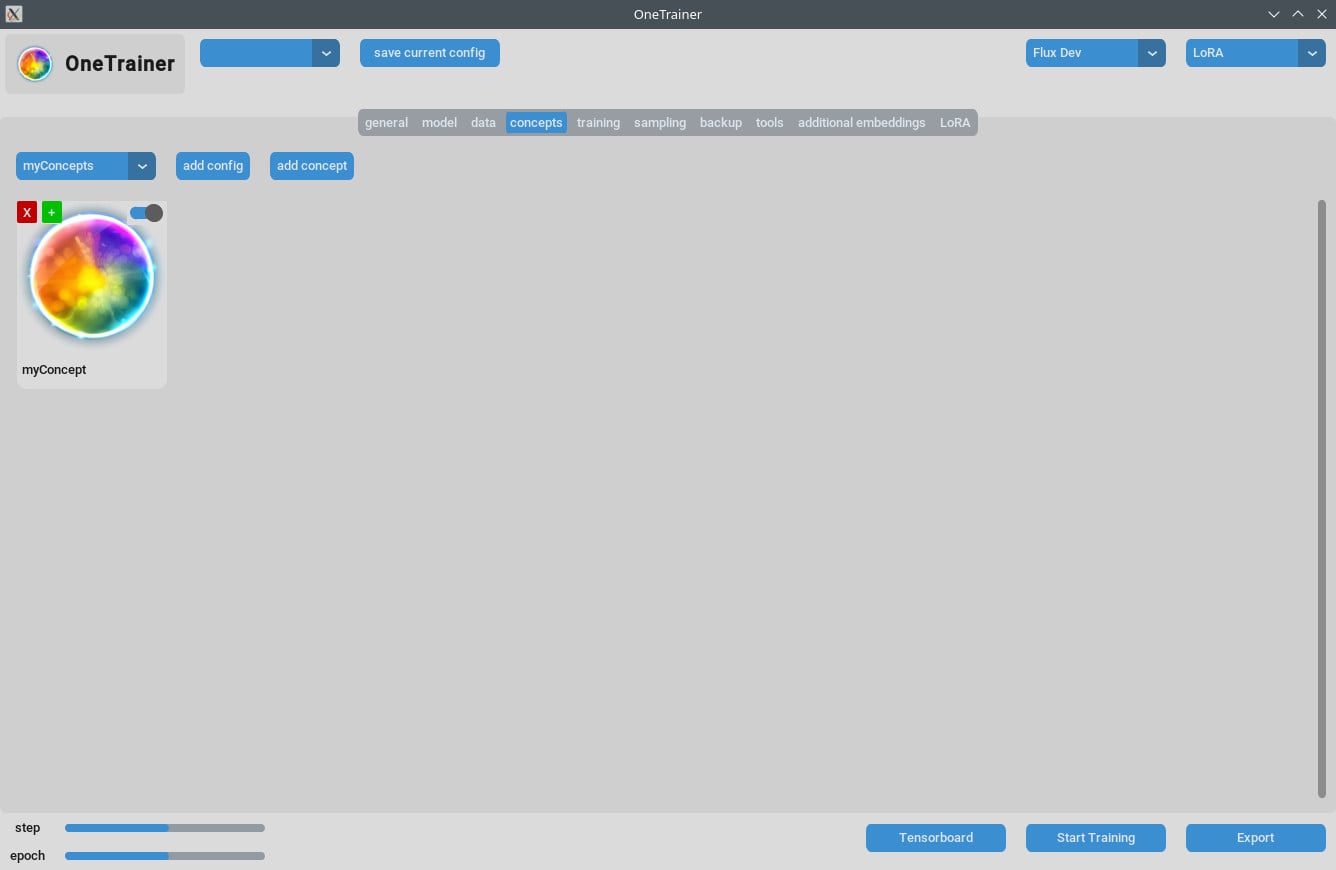
Vorbereitung fürs Training
Modell Auswahl
Zuerst, schau, dass du das richtige Modell Flux AI ausgewählt hast. OneTrainer unterstützt verschiedene Modelle, einschließlich Flux.1 dev, pro und schnell. Stell sicher, dass du ein Modell benutzt, das zu deinem Projekt passt.
- Modell besorgen: Lade das gewünschte Modell von offiziellen Seiten wie Hugging Face runter.
- Modell laden: In OneTrainer gehst du zu den Modelleinstellungen und lädst die Modell-Dateien.
Umgebung einrichten
Hardware-Anforderungen:
- GPU: Mindestens eine 3060 wird empfohlen. Mit einer 4090 läuft's besser.
- VRAM: Mindestens 12 GB, um höhere Auflösungen zu schaffen.
- RAM: Mindestens 10 GB RAM sind ratsam, mehr ist besser.
Software-Anforderungen:
- Betriebssystem: Wurde sowohl auf Windows als auch auf Linux getestet.
- Abhängigkeiten: Alle nötigen Abhängigkeiten sollten installiert sein. Schau in die Dokumentation von OneTrainer für eine Liste von erforderlichen Bibliotheken und Tools.
Detaillierte Einstellungen und Konfigurationen
Konzept-Tab/Allgemeine Einstellungen
- Wiederholungen: Setze
Wiederholungenauf 1. Die Anzahl der Wiederholungen kannst du überAnzahl der Epochenim Trainings-Tab steuern. - Prompt-Quelle: Benutz "aus einer einzelnen Textdatei", wenn du ein „Auslöserwort“ statt individueller Beschreibungen pro Bild haben möchtest. Zeig auf eine Textdatei mit deinem Auslöserwort/Phrase.
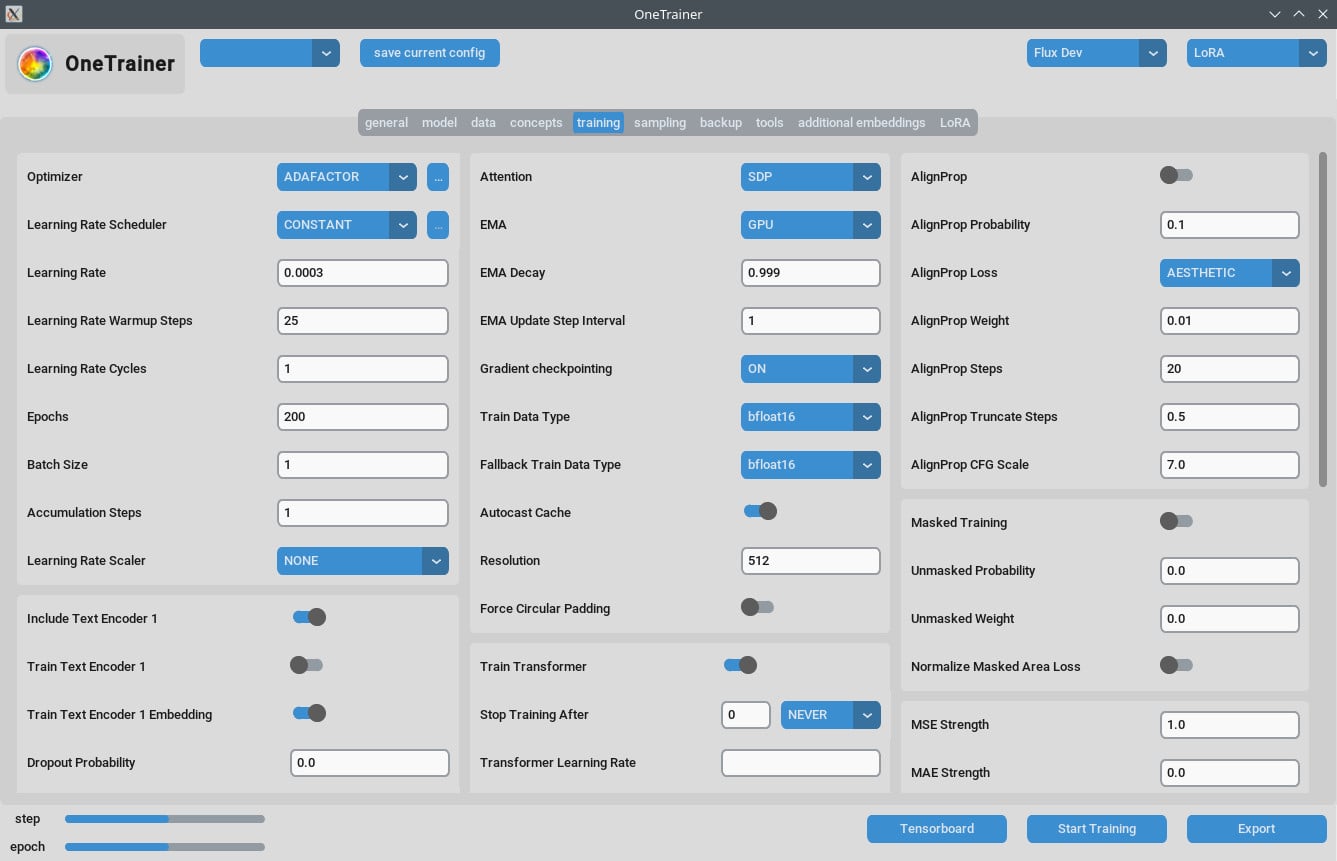
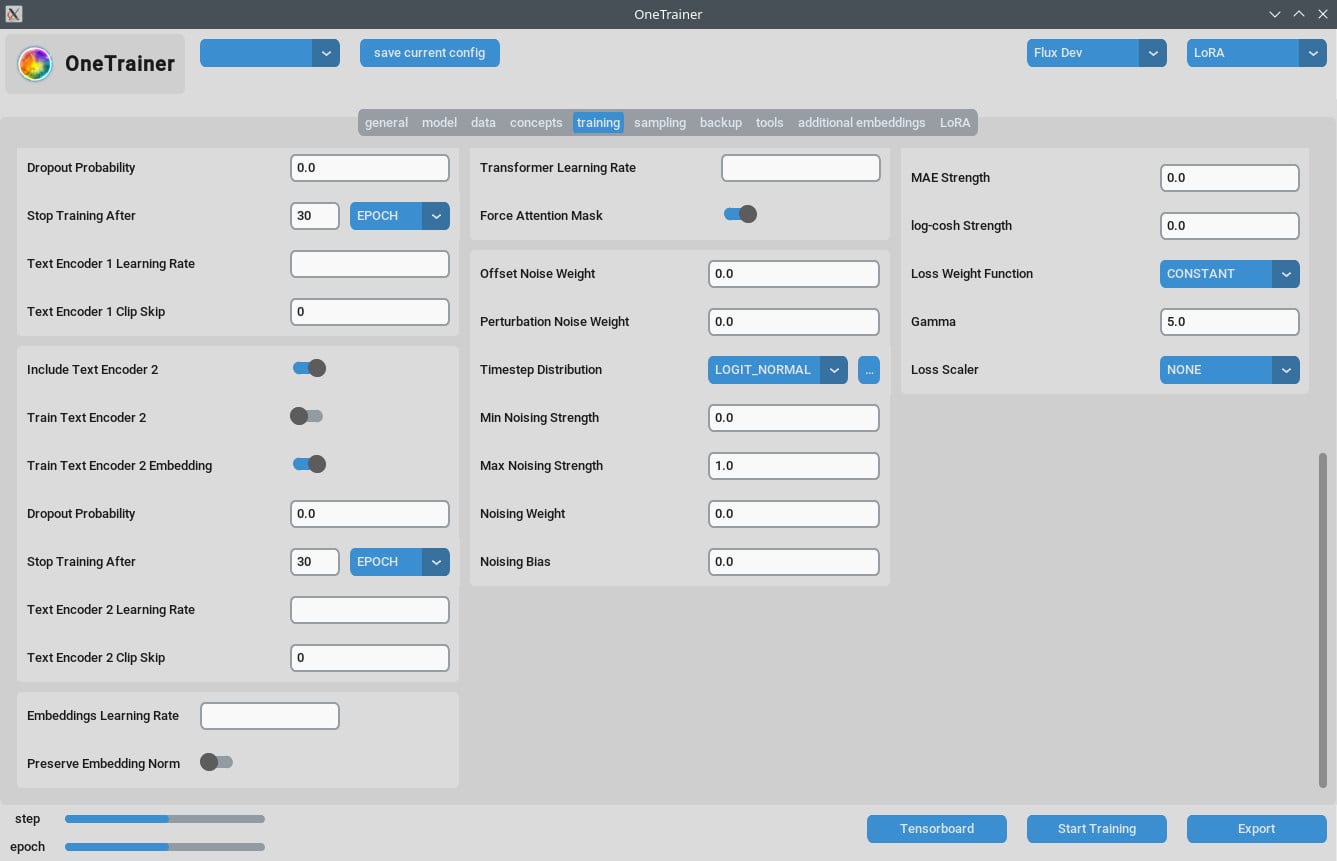
Trainings-Tab
Auflösungseinstellungen
- Für bessere Qualität:
- Setze
Auflösungauf 768 oder 1024 für hochwertigere Outputs.
- Setze
- EMA-Einstellungen:
- EMA: Nutze es während der SDXL-Trainings.
- EMA GPU: Um VRAM zu sparen, setze EMA von "GPU" auf "AUS."
- Lernrate:
- Ein Startpunkt könnte 0.0003 oder 0.0004 sein. Anpassungen je nach deinem Bedarf vornehmen.
- Anzahl der Epochen:
- Typischerweise zeigen 40 Epochen gute Ergebnisse. Je nach Komplexität deines Datensatzes anpassen.
LoRA-Tab
- Rank und Alpha:
- Halte diese Werte gleich (z.B. 64/64, 32/32) oder passe deine Lernrate an.
- Ergebnis-Modelle von LoRA:
- Achte darauf, dass Updates übernommen werden, wenn du neuere ComfyUI-Versionen verwendest.
Performance-Optimierung
- Gradient-Checkpointing:
- Versuch das abzuschalten, wenn du langsame Geschwindigkeiten erlebst, besonders wenn deine Hardware mehr VRAM hat.
- bf16 vs nfloat4:
- Im "Modell"-Tab, schalte
Übersteuern der vorherigen Datentypenauf bf16, um eventuell die Qualität zu steigern. Diese Einstellung beeinflusst VRAM und Geschwindigkeit.
- Im "Modell"-Tab, schalte
Umgang mit Sampling-Problemen
- Einige Nutzer hatten Out Of Memory (OOM)-Fehler beim Sampling. Achte darauf, dass deine GPU genug VRAM hat.
- Halte OneTrainer regelmäßig auf dem neuesten Stand, um Fehlerbehebungen und Patches einzuarbeiten.
Tipps für Multi-Konzept-Training
Aktuelle Einschränkungen
- Mehrere Personen mit verschiedenen Auslösern in derselben Sitzung zu trainieren, funktioniert oft nicht.
- Verschiedene Objekte oder Situationen (z.B. Trainingsschuhe und spezielle Autos) funktionieren besser.
Beste Praktiken
- Kurze Beschreibungen:
- Verwende kurze, natürliche Beschreibungen. Die funktionieren in nur ein paar Hundert Schritten meist gut.
- LoRAs stapeln:
- Das Stapeln eines Konzept- und Charakter-LoRA bringt bessere Ergebnisse als kombiniertes Training.
Beschreibungen und Datenmanagement
- Organisiere deine Trainingsdaten sorgfältig. Die Anzahl der Epochen hängt von der Komplexität deiner Daten ab.
- Kurze, präzise Beschreibungen können das Training deutlich effizienter machen.
FAQs
Q1: Kann ich OneTrainer für Modelle außer Flux.1 verwenden?
Ja, OneTrainer unterstützt SD 1.5, SDXL und mehr. Die Einstellungen können je nach Modell variieren.
Q2: Verwendet OneTrainer automatisch den Konzeptnamen als Auslöserwort?
Ja, der Konzeptname kann als Auslöserwort fungieren. Achte darauf, dass es für dein Projekt sinnvoll ist.
Q3: Wie kann ich VRAM während des Trainings effektiv managen?
Setze Gradient-Checkpointing auf CPU_OFFLOAD. Diese Einstellung hilft, den VRAM-Verbrauch zu reduzieren, ohne die Geschwindigkeit stark zu beeinflussen.
Q4: Was bewirkt die Verwendung von NF4 im Vergleich zu Full Precision Layers?
NF4 reduziert den VRAM-Verbrauch, könnte aber die Qualität leicht vermindern. Full Precision Layers halten die Qualität, benötigen aber mehr VRAM.
Q5: Wie kann ich die Größe meines LoRA-Modells verringern?
Du kannst die Werte für Rank und Alpha reduzieren oder den LoRA-Gewichtsdaten-Typ auf bfloat16 setzen. Das reduziert die Größe, kann aber die Qualität beeinträchtigen.
Q6: Kann OneTrainer Multi-Resolution-Training behandeln?
Ja, OneTrainer unterstützt Multi-Resolution-Training. Folge den Richtlinien im OneTrainer-Wiki für die Einrichtung.
Q7: Meine Bilder erscheinen pink und statisch, wenn ich DoRA benutze. Was soll ich tun?
Überprüfe deine Einstellungen für die Attention-Schicht. Vermeide die Verwendung von "voll" für die Attention-Schichten, da das das Problem verursachen könnte.
Q8: Wie gehe ich mit mehreren Subjekten in OneTrainer um?
Nutze ausgewogenes Training, indem du unterschiedliche Wiederholungswerte für verschiedene Subjekte festlegst. Organisiere die Daten sorgfältig, damit beide Subjekte gleich viel Training bekommen.
Q9: Gibt es einen „Split Mode“-Äquivalent in OneTrainer?
OneTrainer hat keinen „Split Mode“. Stattdessen kannst du Einstellungen wie CPU_OFFLOAD für Gradient-Checkpointing verwenden, um den VRAM effektiver zu managen.
Q10: Können die OneTrainer-Einstellungen für bessere Qualität bei höherem VRAM-Verbrauch angepasst werden?
Ja, erhöhe die Auflösung und passe die Datentypen und Einstellungen für das Gradient-Checkpointing an, um die Qualität zu verbessern.
Diese Anleitung gibt dir alle nötigen Schritte, Einstellungen und Tipps zur Fehlersuche, um OneTrainer mit Flux AI-Modellen effektiv zu nutzen. Viel Spaß beim Training!