
- pub
Flux.1 LoRA 및 DoRA 훈련을 위한 최적화된 OneTrainer 설정과 팁 (20% 더 빠름)
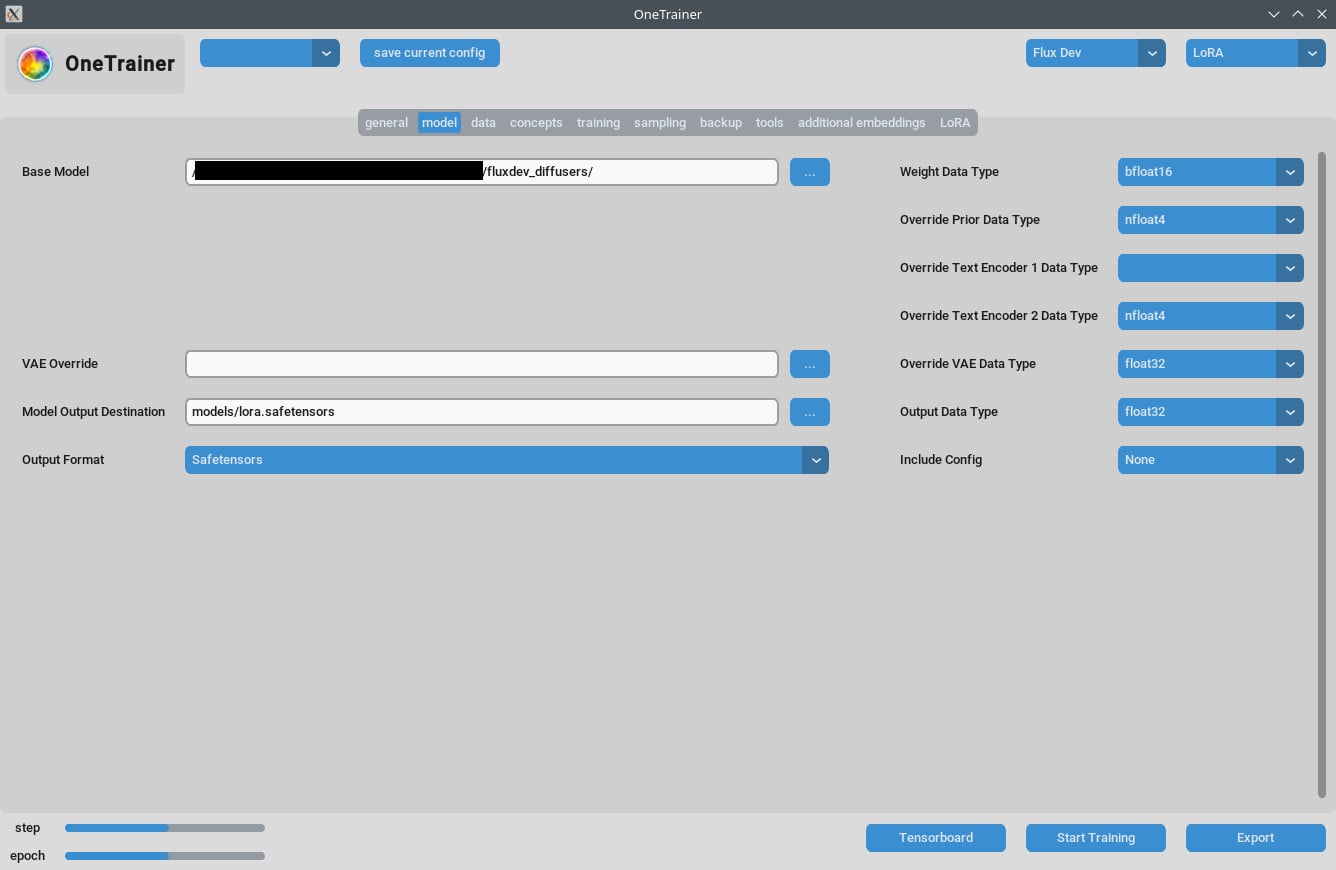
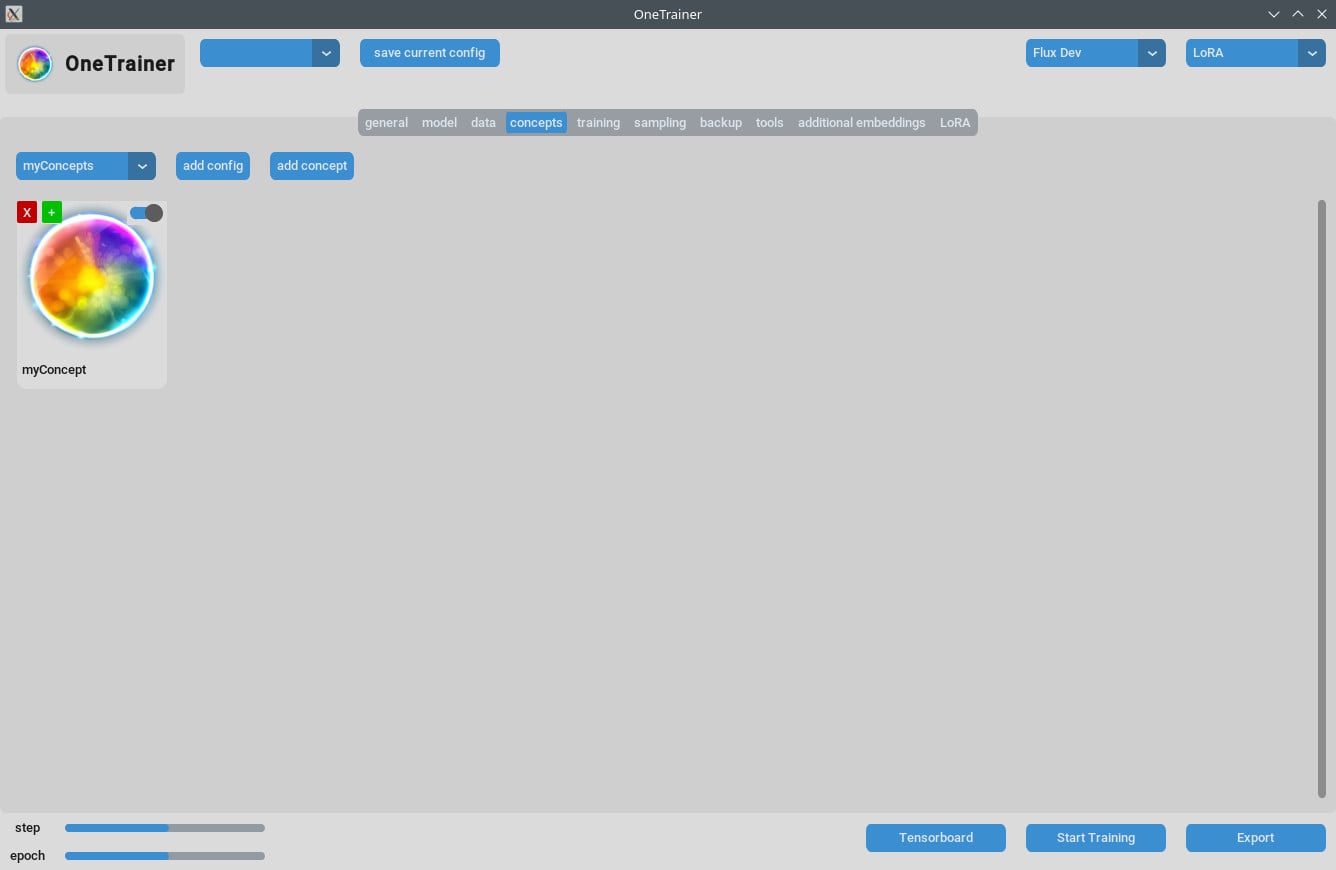
훈련 준비하기
모델 선택하기
먼저, Flux AI 모델이 맞는지 확인해봐. OneTrainer는 Flux, 1 dev, pro, schnall 같은 여러 모델을 지원해. 네 프로젝트에 맞는 모델을 써야 해.
- 모델 얻기: Hugging Face 같은 공식 소스에서 모델을 다운로드 해.
- 모델 로드하기: OneTrainer에서 모델 설정으로 가서 모델 파일을 로드해.
환경 설정하기
하드웨어 요구 사항:
- GPU: 최소 3060을 추천해. 4090으로 훈련하면 성능이 더 좋아.
- VRAM: 고해상도를 처리하려면 최소 12GB는 필요해.
- RAM: 최소 10GB RAM을 권장하고, 더 많을수록 좋아.
소프트웨어 요구 사항:
- 운영 체제: Windows와 Linux에서 테스트 되었어.
- 의존성: 모든 의존성이 설치 되어있는지 확인해. 필요한 라이브러리와 도구는 OneTrainer 문서에서 확인해.
자세한 설정과 구성
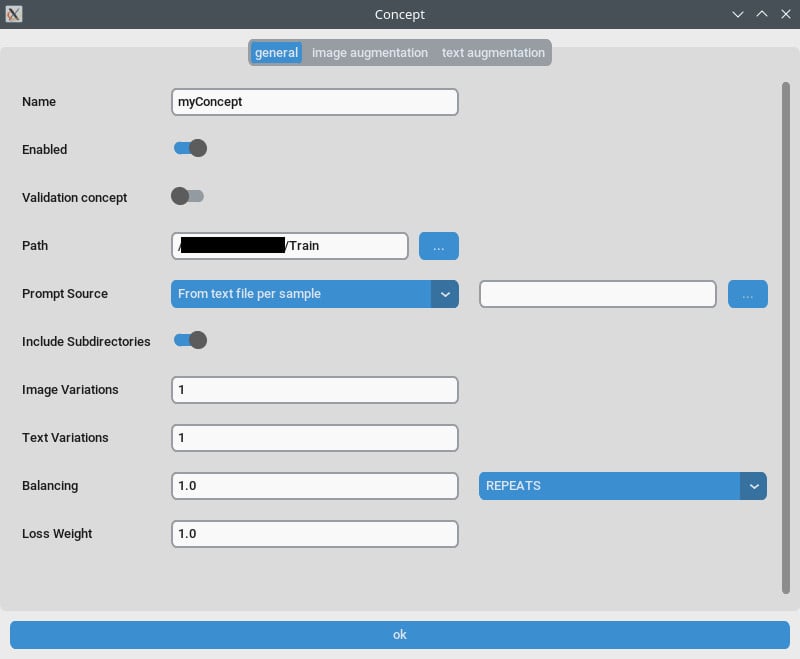
컨셉 탭/일반 설정
- 반복:
Repeats를 1로 설정해. 훈련 탭의Number of Epochs로 반복 수를 조절할 수 있어. - 프롬프트 소스: 이미지 각각의 캡션 대신 "단일 텍스트 파일에서" 선택해. 텍스트 파일에 있는 트리거 단어/구문으로 이 설정을 정해.
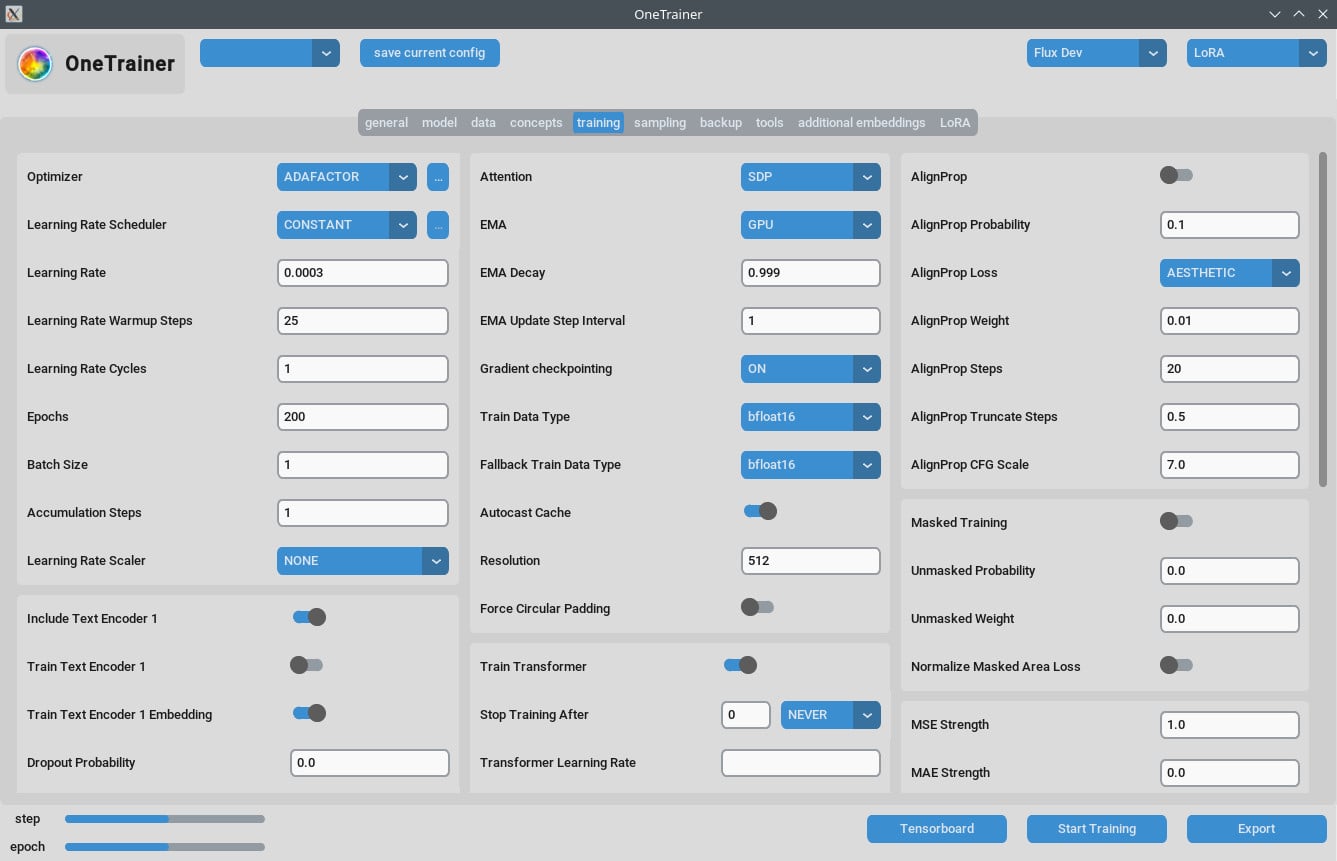
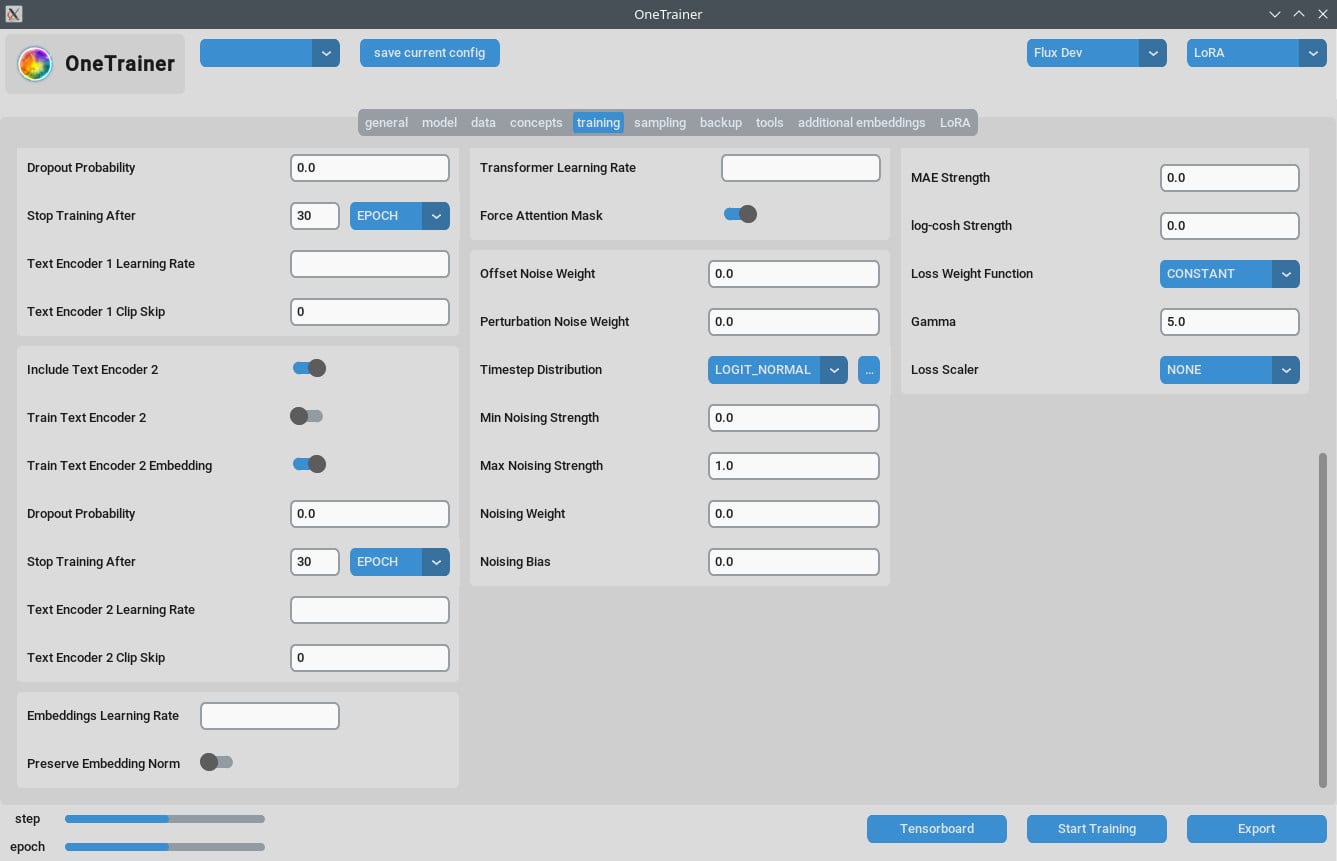
훈련 탭
해상도 설정
- 더 좋은 품질을 위해:
- 해상도를 768이나 1024로 설정해.
- EMA 설정:
- EMA: SDXL 훈련 중에 사용해.
- EMA GPU: VRAM을 아끼려면 EMA를 "GPU"에서 "OFF"로 해.
- 학습률:
- 시작할 때 0.0003이나 0.0004로 해봐. 너의 필요에 맞게 조정해.
- 에포크 수:
- 보통 40 에포크면 좋은 결과를 내. 데이터셋의 복잡성에 따라서 조정해.
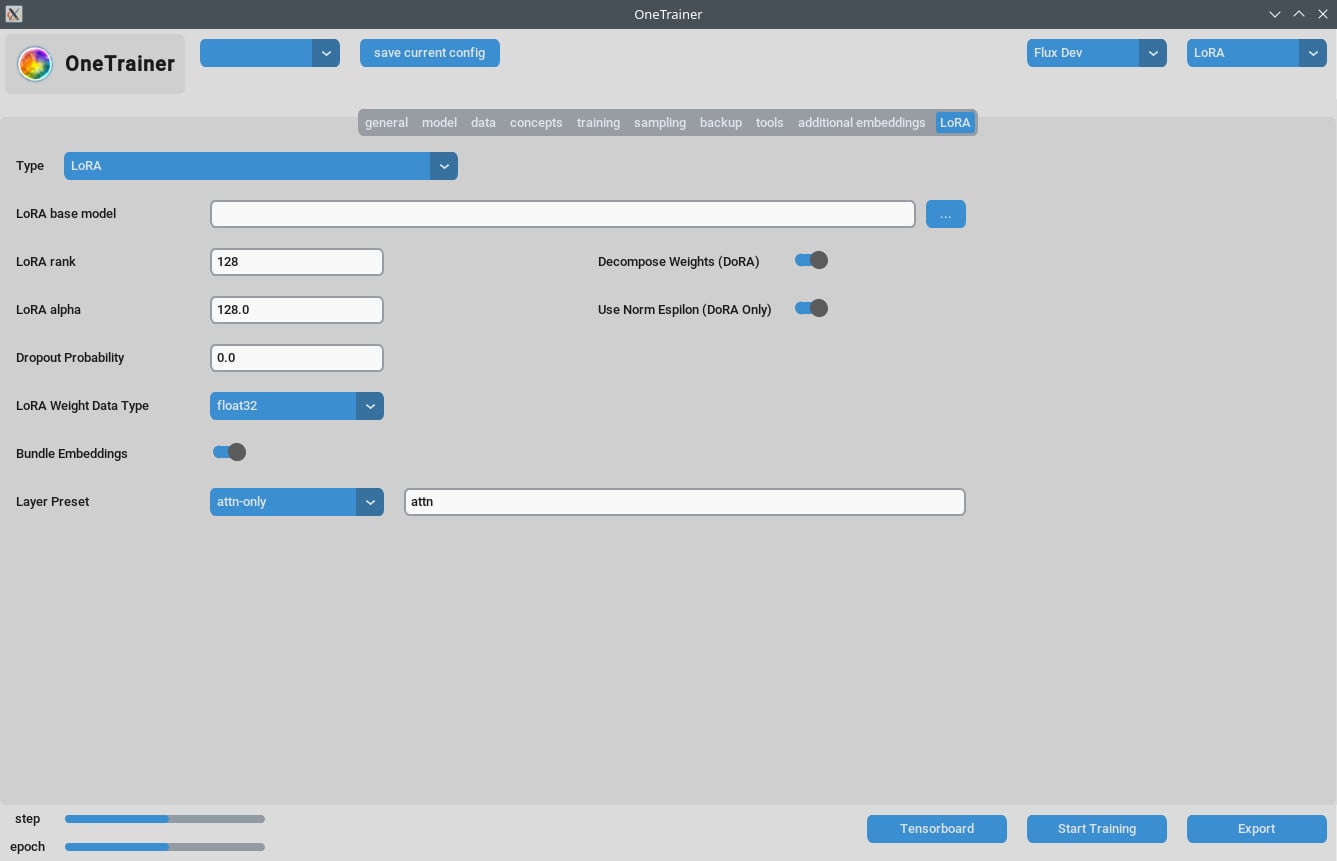
LoRA 탭
- 랭크와 알파:
- 이 값들을 같게 유지해 (예: 64/64, 32/32) 아니면 학습률에 맞게 조정해.
- 결과 LoRA 모델:
- 최근 ComfyUI 버전에서 사용한다면 업데이트가 적용되어야 해.
성능 최적화
- 그래디언트 체크포인팅:
- 속도가 느리다면 이걸 꺼보는 것도 좋아, 특히 하드웨어가 더 높은 VRAM을 지원하면 그렇고.
- bf16 vs nfloat4:
- "모델" 탭에서
Override Prior Data Type를 bf16으로 바꾸면 품질이 올라갈 수 있어. 이 설정은 VRAM과 속도에 영향을 줘.
- "모델" 탭에서
샘플링 문제 처리하기
- 어떤 사용자들은 샘플링 중에 메모리 부족 (OOM) 오류가 발생했어. GPU에 충분한 VRAM이 있는지 확인해.
- OneTrainer를 정기적으로 업데이트해서 버그 수정과 패치를 적용해.
다중 컨셉 훈련 팁
현재 제한 사항
- 같은 세션에서 서로 다른 트리거 단어로 여러 사람을 훈련하는 건 잘 안 돼.
- 다른 객체나 상황(예: 운동화와 특정 자동차)은 더 잘 작동해.
최고의 방법
- 짧은 캡션:
- 짧고 자연스러운 캡션을 사용해. 이게 보통 몇 백 스텝만으로도 잘 맞아.
- LoRA 쌓기:
- 개념 LoRA와 캐릭터 LoRA를 쌓는 게 Combined Training보다 더 좋은 결과를 내.
캡션과 데이터 관리
- 훈련 데이터를 잘 정리해. 에포크 수는 데이터의 복잡성에 달려 있어.
- 짧고 정확한 캡션이 훈련 효율성을 크게 높일 수 있어.
자주 묻는 질문
Q1: OneTrainer를 Flux.1 외의 모델에서 사용할 수 있어?
응, OneTrainer는 SD 1.5, SDXL 같은 모델도 지원해. 설정은 모델에 따라서 달라질 거야.
Q2: OneTrainer는 자동으로 개념 이름을 트리거 단어로 사용해?
응, 개념 이름이 트리거 단어로 작용할 수 있어. 네 프로젝트에 맞는 의미 있는 이름으로 설정해.
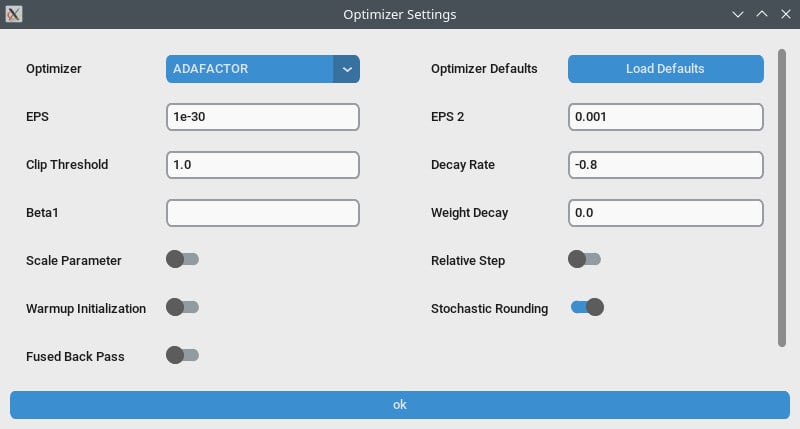
Q3: 훈련 중에 VRAM을 효과적으로 관리하려면 어떻게 해?
Gradient Checkpointing을 CPU_OFFLOAD로 설정해. 이 설정이 VRAM 사용량을 줄이면서 속도에 큰 영향은 없어.
Q4: NF4와 전체 정밀도 레이어를 사용할 때의 영향은 뭐야?
NF4는 VRAM 사용량을 줄이지만 품질이 약간 떨어질 수 있어. 전체 정밀도 레이어는 품질을 유지하지만 더 많은 VRAM이 필요해.
Q5: LoRA 모델의 크기를 줄이는 방법은?
Rank와 Alpha 값을 줄이거나 LoRA weight data type을 bfloat16로 설정해. 이게 크기를 줄이지만 품질에 영향 줄 수 있어.
Q6: OneTrainer가 다중 해상도 훈련을 처리할 수 있어?
응, OneTrainer는 다중 해상도 훈련을 지원해. 설정 방법은 OneTrainer 위키에서 확인해.
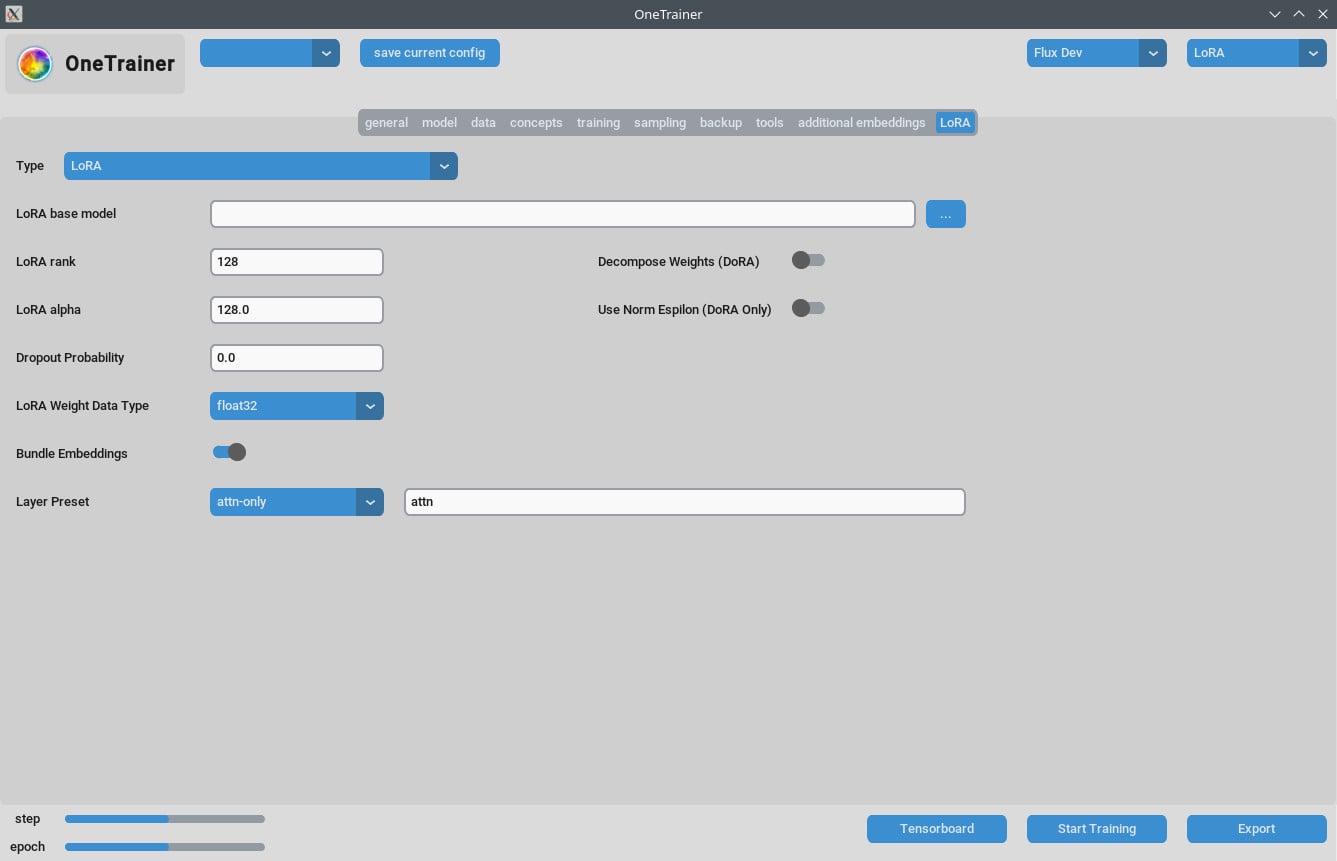
Q7: DoRA를 사용할 때 이미지가 분홍색 정적처럼 보여. 어떻게 해야 해?
어텐션 레이어 설정을 확인해. 어텐션 레이어를 "full"로 쓰지 않는 게 좋을 수 있어, 이게 문제를 일으킬 수 있어.
Q8: OneTrainer에서 여러 대상을 다루려면 어떻게 해야 해?
각 대상을 위해 다른 반복 값을 설정해서 균형 잡힌 훈련을 해. 데이터를 잘 정리해서 두 대상이 고르게 훈련받도록 해.
Q9: OneTrainer에 '스플릿 모드' 같은 기능이 있어?
OneTrainer에는 '스플릿 모드'가 없어. 대신 Gradient Checkpointing의 CPU_OFFLOAD 설정을 사용해 VRAM을 더 효과적으로 관리해.
Q10: 제 품질을 높이기 위해서 VRAM 사용량을 늘리는 설정을 조정할 수 있어?
응, 해상도를 올리고 데이터 타입과 그래디언트 체크포인팅 설정을 조정해 품질을 높일 수 있어.
이 가이드가 Flux AI 모델로 OneTrainer를 효과적으로 사용하는 데 필요한 모든 단계, 설정, 문제 해결 팁을 제공해. 훈련 잘 해!